LLM基础
LLM 英文全称为 Large Language Model,即大语言模型。
LLM 与 AI
LLM 仅仅是 AI 的一个分支。
AI:Artificial Intelligence 任何能够让机器模仿人类行为的技术
- 交通程序导航
- 游戏里面的NPC
AI 下面有很多的分支:
- 自动驾驶
- 机器人
- 处理语言模型
- 处理图像模型
- 语音识别
- .....
机器学习(Machine Learning)就是其中之一。
机器学习
人类不直接给出决策规则,通过一套算法,让系统能够根据示例自己去学习,自己来做出决策。
深度学习
机器学习下的一个分支,这是一种 受到人脑神经系统的启发而发展出来的一种机器学习方法。通过“多层神经网络”来自动从数据中学习特征和模式,尤其擅长处理图像、语音、文本等高维、复杂的数据。
这里仅仅是受到人脑神经的启发,不等价于复制了整个人脑。
多层:
输入层 --> 隐藏层1 ---> 隐藏层2 .... ---> 输出层
每一层包含多个神经元:
- 对输入进行加权求和
- 通过激活函数产生输出
- 输出传递给下一层
这个结构越深(隐藏层越多),模型能够学到的模式就越复杂
深度学习分支中,也不是一开始就有 Transformer 架构(模型),也是一步一步发展过来的:
- CNN:卷积神经网络,图像任务为主
- RNN / LSTM:循环神经网络,序列任务为主
- GAN:生成对抗网络,生成类任务
- Transformer:多模态/语言模型/NLP为主(现已统治 DL)
| 时间 | 模型名 | 类型 | 应用领域 | 备注 |
|---|---|---|---|---|
| 1986 | MLP + 反向传播 | 通用神经网络 | 初代神经网络 | Hinton 提出反向传播算法 |
| 1990s | RNN | 循环网络 | 时间序列、语言建模 | 可记忆序列,但存在梯度消失问题 |
| 1997 | LSTM | RNN 变体 | 更长序列建模 | 解决 RNN 梯度问题 |
| 1998 | LeNet-5 | CNN | 图像识别(手写数字) | 深度学习在图像上的首次成功 |
| 2012 | AlexNet | CNN | 图像识别 | ImageNet 比赛震撼业界,DL 大爆发 |
| 2014 | GAN | 生成模型 | 图像生成、风格迁移 | 生成对抗学习首次提出 |
| 2014 | Seq2Seq + Attention | RNN + 注意力 | 机器翻译 | 注意力机制前身,奠基 Transformer |
| 2017 | Transformer | 自注意力 | NLP,现扩展至图像/音频/多模态 | 无需循环/卷积,端到端强大架构 |
| 2018+ | BERT, GPT, T5, etc. | LLM | 自然语言处理 | Transformer 进入爆发期 |
| 2021+ | Diffusion Models | 生成模型 | 图像生成(如Stable Diffusion) | GAN 之外的新方向 |
Transformer 模型现在已经统治了深度学习领域:
| 模型 | 是否支持序列输入 | 是否并行计算 | 主要用于 | 是否已被 Transformer 替代 |
|---|---|---|---|---|
| RNN | 是 | 否(顺序依赖) | 文本、语音 | 是 大多数已被 Transformer 替代 |
| LSTM/GRU | 是 | 否 | 长序列建模 | 是 被 Transformer 替代 |
| CNN | 否 | 是 | 图像 | 部分视觉任务仍使用 |
| Transformer | 是 | 是 | 文本、图像、音频、代码、视频 | 是 当前主流通用架构 |
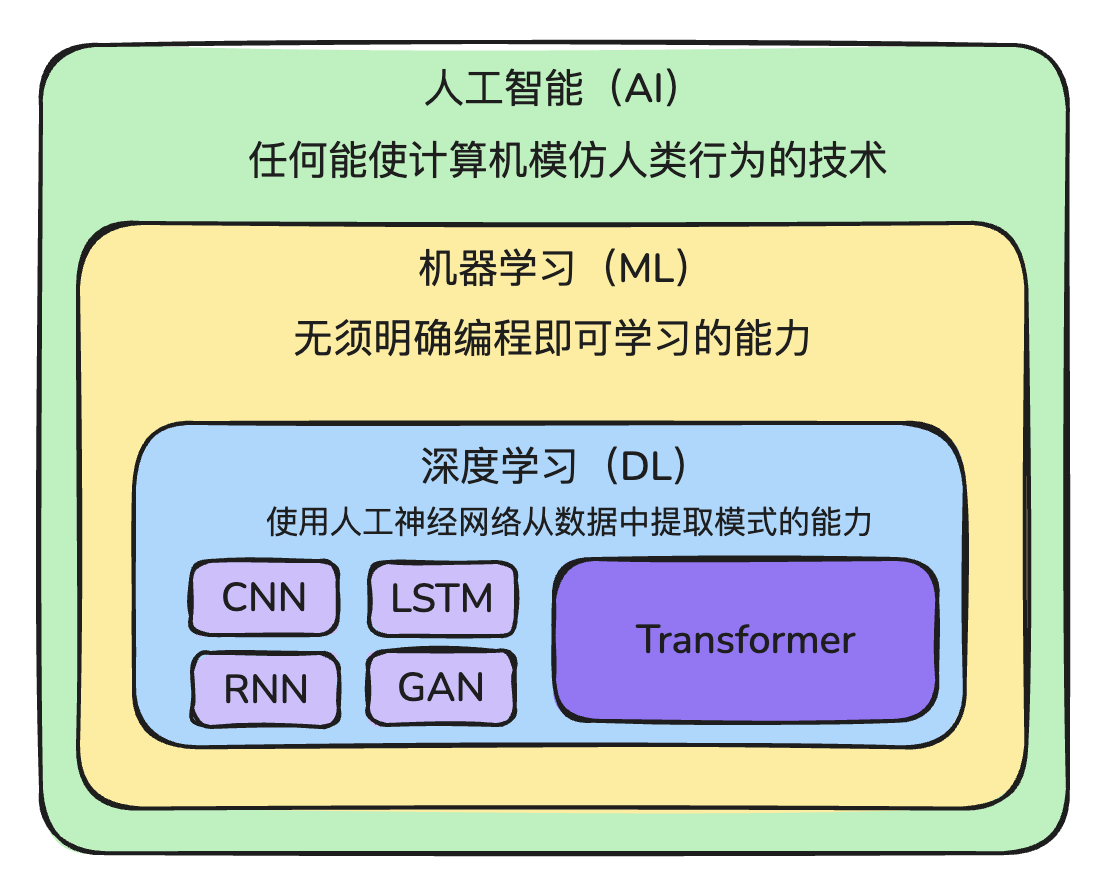
理解上面几个概念之间的关系。
LLM发展史
AI 技术两大核心应用方向
- 计算机视觉(Computer Vision,CV):让计算机看懂图片和视频,模仿人类的眼睛
- 自然语言处理(Natural Language Processing,NLP):让计算机能够理解人类语言,甚至可以进行交流
早期 AI 的研究突破基本都是和 CV 相关的,这几年 NLP 属于后来居上。
思考:何为语言?信息又如何传播?
最早的语言,是以 声音 为媒介,通过说话进行传送的,因此使用同一种语言就显得非常重要。
不过其实,早在两千多年前,古人就研究过这个问题。古代版的普通话叫“雅言”。春秋时期,孔子的三千弟子来自五湖四海,这就必然需要孔子用一种被大家共同认可的语言来讲学。孔子用什么来讲学呢?《论语・述而第七》中记载“子所雅言,《诗》、《书》、执礼,皆雅言也。”
口头传播信息有明显的的缺点,那就是 信息非常不易积累,也很难传播。原始的人类开始使用结绳、刻契、图画的方法辅助记事,后来又用图形符号来简化、取代图画。当图形符号简化到一定程度,并形成与语言的特定对应的时候,早期的文字就形成了。因此,无论是最古老的象形文字、楔形文字,还是甲骨文,以及现代文字,它们的作用只有一个:承载信息。

承载信息:
- 声音
- 文字
没有口头话语,没有书面文字,我们就无法沟通。所以,语言是信息的载体。
口头话语和书面文字都是语言的重要组成部分。有了语言,就有了信息沟通的基础。不过,除了语言这个信息载体之外,我们需要在信息的通道中为语言编码和解码。
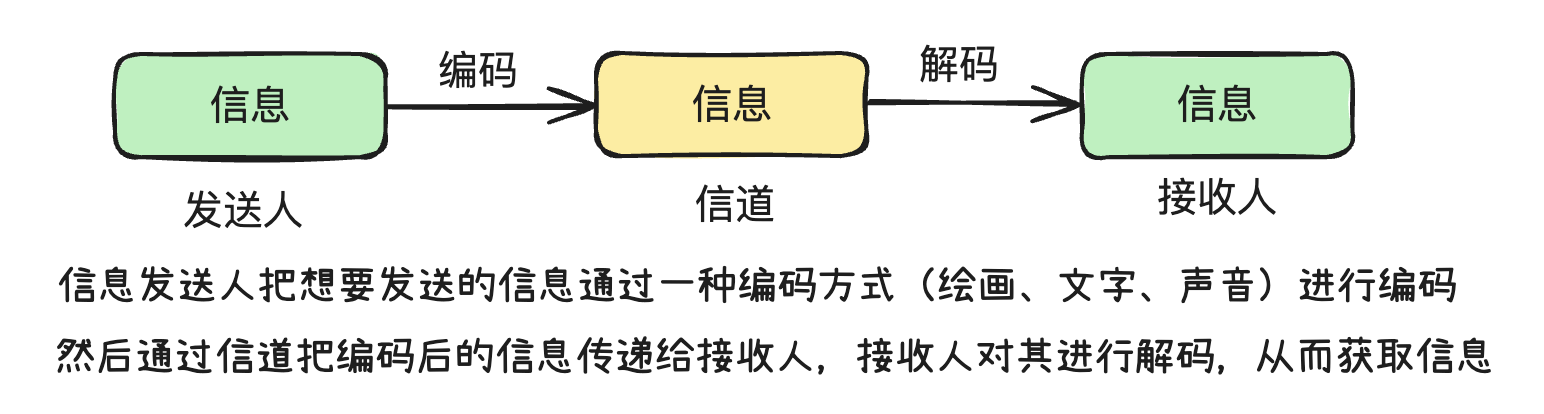
同理,计算机也不能直接理解人类的自然语言,因为缺少编码和解码的过程。因此,要让计算机理解我们人类的语言,就要对语言进行编码,将其转换为计算机能够读懂的形式。
NLP 的核心任务:就是让人类语言进行某种形式的编码以及解码,让计算机能够理解人类的语言。
只有理解了人类的语言,才能完成人类给它下达的任务。
NLP演进史
分为如下 4 个阶段:
- 起源
- 基于规则
- 基于统计
- 深度学习和大数据驱动
1. 起源
NLP 的起源可以追溯到阿兰・图灵在 20 世纪 50 年代提出的图灵测试。
图灵测试的基本思想:如果一个计算机程序能在自然语言对话中表现得像一个人,那么我们可以说它具有智能。
2. 基于规则
在随后的数十年中,人们尝试通过基于语法和语义规则的方法来解决 NLP 问题。这也是我们人类在学习一门新的语言的时候的主要思路。
- 一门语言的规则就非常非常多,而且十分复杂,几乎没有办法基于语法规则来建模
- 语言是变化的艺术
下图是“现代中文主要语法关系示意图”
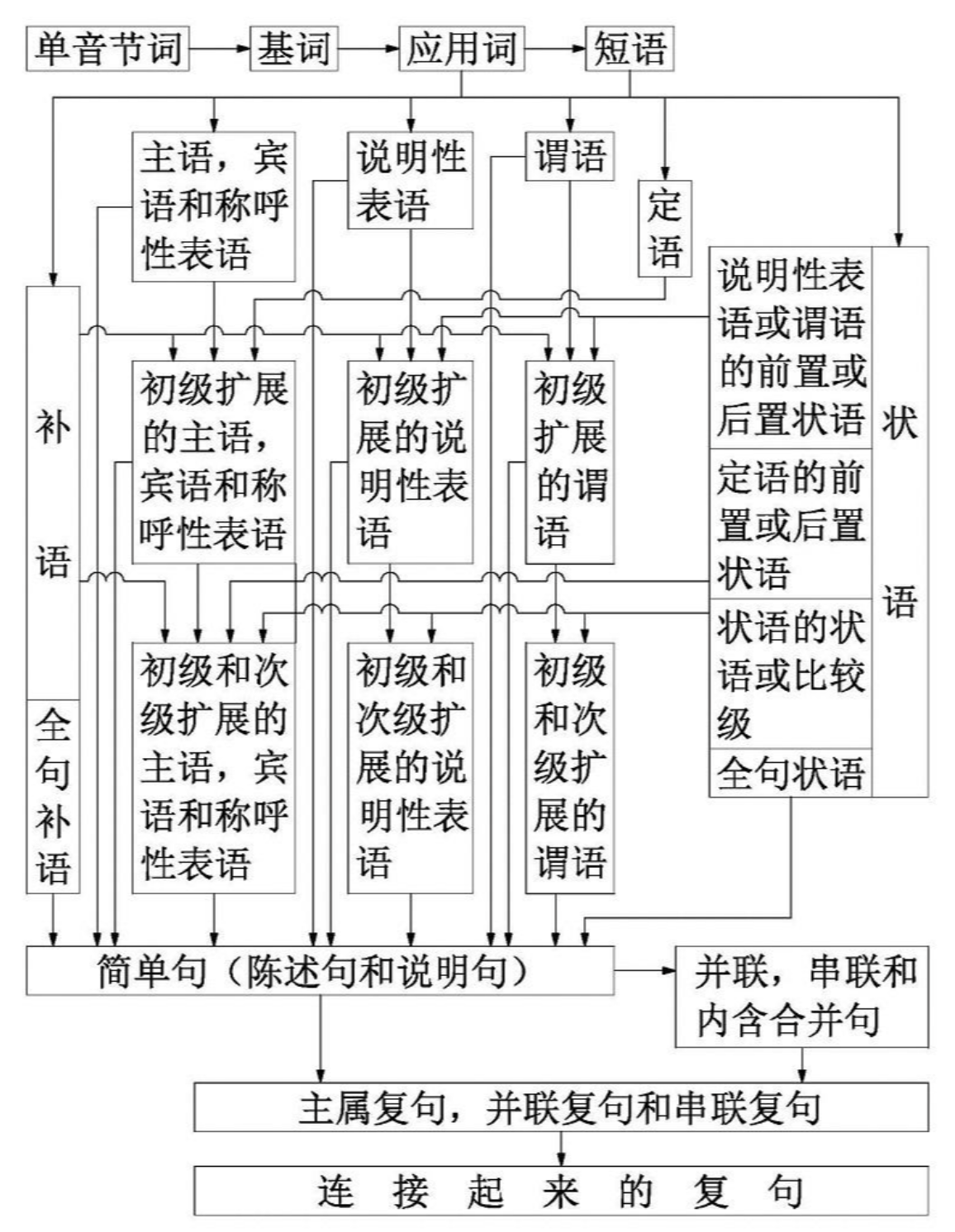
3. 基于统计
1970 年以后,以弗雷德里克・贾里尼克为首的 IBM 科学家们采用了 基于统计 的方法来解决语音识别的问题,终于把一个基于规则的问题转换成了一个数学问题,最终使 NLP 任务的准确率有了质的提升。
至此,人们才纷纷意识到原来基于规则的方法可能是行不通的,采用统计的方法才是一条正确的道路。因此,人们基于统计定义了语言模型(Language Model)
一句话解释什么是语言模型:一种捕捉自然语言中词汇、短语和句子概率分布的统计模型。
| 模型 / 方法 | 简介 |
|---|---|
| Bag-of-Words(BoW) | 最早期的文本表示方法之一,将文本看作词的集合,忽略语序,仅统计词频或词是否出现。广泛用于文本分类和信息检索。 |
| N-Gram 模型 | 最具代表性的统计语言模型之一,利用前 N−1 个词预测下一个词,体现了语言的局部依赖性。 |
| Hidden Markov Model(HMM) | 一种生成式模型,广泛用于语音识别、词性标注等任务,结合状态转移概率和观测概率进行序列建模。 |
| Maximum Entropy Model(最大熵模型) | 判别式模型,可灵活建模特征对输出的影响,常用于命名实体识别、文本分类等任务。 |
| IBM 模型(1~5) | IBM 提出的统计机器翻译模型,专注于词对齐、翻译概率和句子结构建模,对早期翻译系统影响深远。 |
| BLEU 指标(虽然不是模型,但重要) | 一种用于评估机器翻译结果的指标,衡量候选翻译与参考翻译的 n-gram 重合度,是机器翻译研究的重要标准。 |
这个时期,语言模型(统计模型)就已经出现了。这个时期还不能称之为大语言模型,只能叫做语言模型。
4. 深度学习和大数据驱动
在统计方法被广泛应用之后,NLP 迎来了关键的技术飞跃——以 深度学习 和 大数据 为代表的新范式逐步取代了传统的统计模型,成为主流。这一阶段可以大致分为两个浪潮:
- 第一波(2013~2018):深度学习技术开始应用于 NLP,词向量(word embedding)等方法显著提升了模型的表示能力;
- 第二波(2018~至今):以 Transformer 为核心架构的大规模预训练模型兴起,依托海量语料数据,实现了更强的语言理解与生成能力。
深度神经网络不再只是用于特定任务的模型,而演变为通用语言表示学习工具,能够从大规模语料中自动学习语言的复杂结构与语义。
这一时期出现的大型预训练语言模型(Large Language Models, LLMs),在众多 NLP 任务中的表现已达到甚至超越人类水平。它们不仅能处理文本分类、语音识别等传统任务,还可以进行高质量的自然语言生成,如对话系统、内容创作、机器翻译等。
该时期一些重要的语言模型:
| 模型 | 简介 |
|---|---|
| Word2Vec(2013) | Google 提出,通过上下文学习词向量,标志着词嵌入(embedding)时代的开始。 |
| GloVe(2014) | Stanford 提出,基于共现矩阵的全局词嵌入方法。 |
| ELMo(2018) | 使用双向 LSTM,能根据上下文动态生成词表示,是上下文词向量的开端。 |
| BERT(2018) | Google 提出,使用 Transformer 编码器,预训练-微调范式奠定现代 NLP 基础。 |
| GPT 系列(2018–至今) | OpenAI 提出,基于 Transformer 解码器,擅长自然语言生成,GPT-3、GPT-4 代表当今 LLM 顶尖水平。 |
| T5(2019) | Google 提出,统一 NLP 任务为“文本到文本”的框架。 |
| RoBERTa、XLNet、ERNIE 等 | 各大公司在 BERT 基础上优化推出的改进版本。 |
| ChatGPT(2022)、GPT-4(2023) | 标志着 LLM 进入应用时代,表现出对话、编程、写作等通用能力。 |
NLP 发展历史表:
| 阶段 | 时间 | 方法 / 模型 | 类型 | 主要用途 | 是否考虑词序 / 语义 |
|---|---|---|---|---|---|
| 规则阶段 | 1950s–1970s | 语法规则、人工模板 | 人工构建规则系统 | 机器翻译、问答系统 | 是(语法结构),否(语义) |
| 统计阶段 | 1970s–2010s | Bag-of-Words (BoW) | 特征表示方法 | 文本分类、情感分析 | 否 |
| TF-IDF | 加权特征表示 | 文本检索、关键词提取 | 否 | ||
| N-Gram | 统计语言模型 | 语言建模、机器翻译 | 是(局部上下文),否(长依赖) | ||
| HMM | 概率生成模型 | 词性标注、语音识别 | 是 | ||
| IBM 模型(1–5) | 对齐翻译模型 | 统计机器翻译 | 是(局部) | ||
| 深度学习阶段 | 2013–2018 | Word2Vec | 分布式词向量 | 构建语义空间、分类器输入 | 否(静态嵌入) |
| GloVe | 基于矩阵的词向量 | 同上 | 否 | ||
| ELMo | 上下文词向量(LSTM) | 命名实体识别、问答等 | 是(局部语境) | ||
| 大语言模型阶段 | 2018–至今 | BERT | 编码器(Transformer) | 预训练 + 微调,适用于多类 NLP 任务 | 是(深层语义) |
| GPT 系列(GPT-2/3/4/5) | 解码器(Transformer) | 文本生成、对话系统 | 是(强上下文与推理能力) | ||
| T5 | 编码器-解码器结构 | 多任务文本生成 | 是 | ||
| ChatGPT | 应用层 LLM | 对话、创作、问答 | 是(多轮对话上下文) |
N-Gram模型
从 1970 年以后人们意识到不能基于规则,得基于统计,从这个时间节点开始,出现了很多语言模型。
基本介绍
N-Gram模型诞生于 1950s–1960s,最早由香农(Claude Shannon)在信息论中提出,用于语言的概率建模。香农在 1951 年的论文中提出,使用 1-gram、2-gram 等方法估计英文文本的概率。前面的 N 是一个数字,表示你每次要看几个词,例如:
- 1-Gram(Unigram):只看一个词(不看前面的词)。
- 2-Gram(Bigram):会看前面的一个词。
- 3-Gram(Trigram):会看前面两个词。
- 以此类推…
该模型基于马尔可夫假设。
马尔可夫假设:一个词出现的概率,依赖于它前面的 N-1 个词,而不是整个句子历史。
(厨房)妈妈说:“帮我拿一下冰箱里面的....”
- 鸡蛋
- 牛脑
- 苹果
- ....
在你的大脑中,就会自动的去预测下一个词。
而不会弹出下面的词:
- 飞机
- 汽车
- 电脑
- ....
工作原理
以 Bigram(2-Gram):会看前面的一个词。
假设有这样一个“语料库”,用这些数据来训练模型:
我 爱 吃 苹果
我 爱 吃 香蕉
我 喜欢 吃 苹果
Bigram 模型会根据一个词统计下一个词出现的概率,这里可以数一数所有词对:
| 前一个词 | 下一个词 | 次数 |
|---|---|---|
| 我 | 爱 | 2 次 |
| 我 | 喜欢 | 1 次 |
| 爱 | 吃 | 2 次 |
| 喜欢 | 吃 | 1 次 |
| 吃 | 苹果 | 2 次 |
| 吃 | 香蕉 | 1 次 |
根据这个词的组合,就可以去预测一个词的下一个词,比如:
- 我后面出现“爱”的概率是 2/3,出现“喜欢”的概率是 1/3。
- 吃后面出现“苹果”的概率是 2/3,出现“香蕉”的概率是 1/3。
所以:
如果你看到“我 爱 吃”,那下一个词大概率是“苹果”!
代码实践
jieba 是 python 里面用于对中文分词的一个库。
“我喜欢吃苹果”
我、喜欢、吃、苹果
import jieba # 导入 jieba 中文分词库
# 导入 defaultdict 和 Counter,用于构建频率统计表
from collections import defaultdict, Counter
# 示例语料库(注意:这些是连续的中文句子,没有空格)
corpus = [
"我喜欢吃苹果",
"我喜欢吃香蕉",
"她喜欢吃葡萄",
"他不喜欢吃香蕉",
"他喜欢吃苹果",
"她喜欢吃草莓"
]
# 1. 构建 Bigram 统计表,格式为 bigrams[前一个词][下一个词] = 出现次数
bigrams = defaultdict(Counter) # 自动初始化嵌套结构,避免手动判断键是否存在
# 遍历每一句话
for sentence in corpus:
words = list(jieba.cut(sentence)) # 使用 jieba 对句子进行分词,返回词列表
# 构建二元组(Bigram):每两个连续词之间的搭配
for i in range(len(words) - 1):
w1, w2 = words[i], words[i + 1] # 当前词和下一个词
bigrams[w1][w2] += 1 # 出现一次就 +1
# 2. 将频率转换成概率,构建 Bigram 概率模型
bigram_probs = {} # 最终保存的是 P(w2 | w1) 的概率表
# 遍历所有前词(w1)
for w1 in bigrams:
total = sum(bigrams[w1].values()) # w1 后面出现所有词的总次数
# 计算每一个 w2 的条件概率:P(w2 | w1) = 频率 / 总数
bigram_probs[w1] = {
w2: count / total for w2, count in bigrams[w1].items()
}
# 3. 定义一个函数:输入一个词,预测它后面最可能出现的词(按概率从大到小排序)
def predict_next_word(word):
if word not in bigram_probs:
return "未知(没有数据)" # 如果这个词从未出现在训练语料中
# 按照概率从高到低排序返回
sorted_probs = sorted(
bigram_probs[word].items(), key=lambda x: x[1], reverse=True
)
return sorted_probs
# 4. 打印所有 Bigram 的条件概率
print("=== Bigram 概率 ===")
for w1 in bigram_probs:
for w2 in bigram_probs[w1]:
prob = bigram_probs[w1][w2]
print(f"P({w2} | {w1}) = {prob:.2f}") # 输出形如:P(吃 | 喜欢) = 1.00
# 5. 测试预测某些词后面最可能出现的词
print("\n=== 预测示例 ===")
for test_word in ["我", "吃", "喜欢", "苹果"]:
print(f"{test_word} → {predict_next_word(test_word)}")
N-Gram 虽然比较简陋,但是它确确实实是基于统计语言建模的起点。
N-Gram缺陷
- 语境短视:只看前 N-1个词,无法理解长距离词性的依赖。
- “我昨天见到一个朋友,他说他非常喜欢编程。”
- 无法泛化:只能记住见过的词语组合,对没有见过的组合无能为力。
- 语料库:我爱吃西瓜(没有葡萄这个词)
- 永远不可能出现:我爱吃葡萄 这种组合
- 不具备语义理解能力
- 无法判断:喜欢 和 爱 这两个词,词性是相似
- 也不能区分:“我打了他”和“他打了我”
总结一句话:只会记录词语搭配,不会理解语言,适用于早期的简单的文本处理任务。
词袋模型
词袋模型(Bag-of-Words)是一种简单的文本表示方法,也是自然语言处理的一个经典模型。它将文本中的词看作一个个独立的个体,不考虑它们在句子中的顺序,只关心每个词出现的频次。
工作原理
词袋模型的核心思想是把:文本表示成一个词频向量,不看词的顺序、句法结构,只关注词是否出现和出现的次数。
词袋模型可以看作是一个装词的口袋,里面有大量的词,零零散散的装在里面的。
假设有三句话作为语料库(Corpus)
句子1:我喜欢吃苹果
句子2:我不喜欢吃香蕉
句子3:她喜欢吃葡萄
第 1 步分词,也就是将每个句子切分成词:
["我", "喜欢", "吃", "苹果"]
["我", "不", "喜欢", "吃", "香蕉"]
["她", "喜欢", "吃", "葡萄"]
第 2 步构建词表,提取所有出现过的唯一词汇,按顺序编号:
可以理解为针对上面的多个词表进行去重,构建一个词表
词表 = ["我", "喜欢", "吃", "苹果", "不", "香蕉", "她", "葡萄"]
这个词表确定了向量的“维度”,共 8 个词,所以向量长度就是 8。
第 3 步构建词频向量,也就是每句话对应一个向量
| 词汇位置 | 我 | 喜欢 | 吃 | 苹果 | 不 | 香蕉 | 她 | 葡萄 |
|---|---|---|---|---|---|---|---|---|
| 句子1 向量 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 |
| 句子2 向量 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 |
| 句子3 向量 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 1 |
这个表就是 BoW 特征向量化后的结果,每句话变成一个“向量”,可以用于计算机处理。
这一点非常重要,也是一个里程碑式的进步,将句子进行向量化之后,意味着可以进行数学计算了。
BoW 相对于 N-Gram 的改进:
| 问题 | N-Gram 的缺陷 | BoW 的解决 |
|---|---|---|
| 维度膨胀严重 | N-Gram 组合数非常多(特别是 Trigram 以上) | BoW 只统计词,不考虑组合,向量维度更小 |
| 数据稀疏严重 | N-Gram 中很多词组组合没出现 | BoW 用词频统计,不会因未出现的组合而归 0,更稳定 |
| 上下文建模复杂 | N-Gram 有上下文,但建模代价大 | BoW 完全不建上下文,适合计算效率优先的场景 |
| 擅长的领域 | N-Gram 通常用于语言建模、生成 | BoW 更适合分类、聚类、检索等任务,不是用来“生成文本”的模型 |
由此可以看出,词袋模型更擅长的任务是:
-
文本分类
-
文本相似度分析
-
信息检索 / 文档排序
[1, 1, 1, 1, 0 , 0, 0, 0]
[1, 1, 1, 0, 0 ,0, 0, 0]
[0, 0, 0, 0, 0, 0, 0, 1]
代码实践
# 导入必要的库
from sklearn.feature_extraction.text import CountVectorizer # 用于构建词袋模型
import jieba # 中文分词库
# 1. 定义原始的中文语料(每个元素是一句话)
corpus = [
"我喜欢吃苹果",
"我不喜欢吃香蕉",
"她喜欢吃葡萄"
]
# 2. 对每个句子进行 jieba 分词,并用空格连接(因为 CountVectorizer 默认按空格分词)
corpus_cut = [" ".join(jieba.cut(sentence)) for sentence in corpus]
# 输出分词后的语料,看一下 jieba 是如何切词的
print("【分词结果】:")
for i, sent in enumerate(corpus_cut):
print(f"句子{i + 1}:{sent}")
# 3. 创建 CountVectorizer 实例(词袋模型工具)
vectorizer = CountVectorizer()
# 4. 训练词袋模型,并将文本转换为词频向量
X = vectorizer.fit_transform(corpus_cut)
# 5. 输出词表(即 BoW 模型所构建的所有词汇)
print("\n【词表】:")
print(vectorizer.get_feature_names_out())
# 6. 输出词频向量(稀疏矩阵 → 转换成数组形式展示)
print("\n【向量表示】:")
print(X.toarray())
将句子转为了向量表示,有什么用呢?
根据向量就可以去评判文本的相似度,以及对文本进行分类。
# 1. 导入必要库
from sklearn.feature_extraction.text import CountVectorizer # 用于构建词袋模型
from sklearn.naive_bayes import MultinomialNB # 朴素贝叶斯分类器
from sklearn.pipeline import make_pipeline # 构建训练流程
import jieba # 中文分词库
import numpy as np
# 2. 准备语料和标签(1 表示正面,0 表示负面)
texts = [
"这家店的菜太难吃了", # 0
"服务态度很差,再也不来了", # 0
"菜品很丰富,味道不错", # 1
"真是一次愉快的用餐体验", # 1
"价格太贵,吃不饱", # 0
"环境很好,服务也周到" # 1
]
labels = [0, 0, 1, 1, 0, 1]
# 3. 使用 jieba 进行分词,并以空格连接适配 CountVectorizer
texts_cut = [" ".join(jieba.cut(text)) for text in texts]
# 输出分词结果
print("【分词结果】:")
for i, text in enumerate(texts_cut):
print(f"句子{i+1}:{text}")
# 4. 初始化 CountVectorizer,并拟合语料库
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(texts_cut)
# 输出词表(词袋)
print("\n【词表(Vocabulary)】:")
print(vectorizer.get_feature_names_out())
# 输出向量表示(词频矩阵)
print("\n【词频向量表示】:")
print(X.toarray())
# 5. 使用朴素贝叶斯分类器进行训练
model = MultinomialNB()
model.fit(X, labels)
# 6. 测试新样本
test_comments = [
"服务不好,东西也难吃", # 0
"饭很好吃,环境也不错", # 1
"太贵了,不推荐", # 0
"下次还会来,真的很满意" # 1
]
test_cut = [" ".join(jieba.cut(comment)) for comment in test_comments]
# 输出测试分词
print("\n【测试集分词】:")
for i, sent in enumerate(test_cut):
print(f"测试{i+1}:{sent}")
# 将测试语句转换为词袋向量
X_test = vectorizer.transform(test_cut)
# 输出测试向量
print("\n【测试集向量】:")
print(X_test.toarray())
# 7. 执行预测
predictions = model.predict(X_test)
# 输出最终预测结果
print("\n【情感预测结果】:")
for comment, label in zip(test_comments, predictions):
print(f"'{comment}' → {'正面' if label == 1 else '负面'}")
词袋模型的缺陷
- 只看词有没有,不看上下文。
- 词序被忽略:在词袋模型里面,“我打了他”和“他打了我”,两句话会被看作是一个意思。
- 没语义泛化能力:模型不知道“满意”和“不错”意思相近,“愉快”和“开心”是同义词。
词元
基本概念
词元,英语里面叫做 Token,是模型里面一个最基本的概念。
词元不仅是模型的输出单位,也是模型的输入单位。发送给模型的提示词(prompt),首先就会被分解为词元。
在 OpenAI 平台官网,提供了在线查看词元的方式。
每一个词元,都会有一个唯一的 ID,因此,最终输入到大模型的数据,是一个词元 ID 列表。
举个例子:
- 假设用户输入的文本为:"Learn about language model tokenization."。
- 首先进行分词:
[Learn] [about] [language] [model] [token] [ization] [.]。 - 查词表映射 ID:每个 token 会被查表映射为一个整数 ID,比如:
[1122, 98, 4012, ...]。 - 最终进入模型:
[1122, 98, 4012, 3305, 2351, 7489, 13]这样的整数列表。
分词策略
词级分词
直接以完整的词为单位进行切分。适用于空格分隔语言,例如英语。
- 粒度较大,语义清晰。
- 对英文常见词效果很好。
- 缺点是无法处理未登录词。
I love natural language processing.
["I", "love", "natural", "language", "processing", "."]
每个单词对应一个词元。如果输入的词是一些新词、或者自造词,就不认识了。不支持 OOV.
OOV 英语全称 Out Of Vocabulary(词汇表),OOV 表示超出了词汇表,从而无法处理这个词。
子词级分词
将词分成更小的子词单元,如词干、前缀、后缀,适合处理未知词。
lovely
love、ly
- 兼顾词级和字符级优点。
- 支持 OOV。
能够处理一些新词以及自造词。
字符级分词
将每个字符作为一个词元,不依赖词典。
Hello
["H", "e", "l", "l", "o"]
- 适合拼写敏感任务(如语言模型、自动补全)。
- 能处理所有字符,OOV 问题消失(不存在造不出来的词)。
- 缺点是序列长度变长,难以建模高级语义结构。
字节级分词
将输入文本首先按 UTF-8 字节切分,再对这些字节组成的序列进行建模或进一步压缩。换句话说,它的基本单位是字节而不是字符或词,因此具有语言无关性。
Hello 😊
[72, 101, 108, 108, 111, 32, 240, 159, 152, 138]
- 前面 6 个是 ASCII 字符(H e l l o 空格)。
- 后面 4 个是 emoji 表情的 UTF-8 编码。
优势:
- 语言无关,对多语言友好。
- 处理 OOV 能力比较强。
- 压缩空间效率高:根据训练数据频率自动构建最佳子词组合,减少 token 总数。
目前 GPT-2 / GPT-3 / GPT-4 均采用的是字节级分词。
不同版本的大模型,分词的结果会有不同,例如在 GPT2 中,Python 代码 elif 会被分为两个词[el、if],但是到了 GPT4 就已经有自己的词元了,会分为 [elif],这一点源于模型对代码的关注度的提升。
不同的语言模型,分词的效果也会不同,举个例子:
ChatGPT真厉害!
GPT4
['Chat', 'G', 'PT', '真', '厉', '害', '!']
BERT
['[UNK]', '真', '厉', '害', '!']
Phi-3
['▁Chat', 'G', 'PT', '真', '厉', '害', '!']
具体如下表:
| 模型 | 分词方法 | 分词器工具 | 是否字节级 | 是否子词级 | OOV问题 |
|---|---|---|---|---|---|
| GPT-2 | Byte-level BPE | tiktoken | 是 | 是 | 无 |
| GPT-4 | Byte-level BPE(改进) | tiktoken | 是 | 是 | 无 |
| BERT | WordPiece | bert-tokenizer | 否 | 是 | 有 [UNK] |
| Phi-3 | SentencePiece (Unigram+BPE) | sentencepiece | 可选 | 是 | 无 |
嵌入
嵌入(Embedding),是一种寻找词和词之间相似性的 NLP 技术,它把词汇各个维度上的特征用数值向量进行表示,利用这些维度上特征的相似程度,就可以判断出哪些词和哪些词语义更加接近。
基本概念
举个例子:假设有这么一段文本
我喜欢小猫和小狗
经过分词器(Tokenizer)处理后,会变成词元 ID 列表:
| 词语 | 词元ID |
|---|---|
| 我 | 1001 |
| 喜欢 | 1002 |
| 小猫 | 2001 |
| 和 | 1003 |
| 小狗 | 2002 |
这些对于模型来讲仍然只是一堆编号,没有任何语义信息。接下来要做的嵌入操作,就是要给这些词添加语义信息。
接下来引入一个 嵌入矩阵(Embedding Matrix),为每个词元嵌入向量信息。向量信息是多维度的,一般能够达到成百上千维度。每一个维度,代表的就是一个语义方向。
在这个例子中,假设就 4 维。如下:
| 向量维度 | 可能的语义方向(隐含) | 小猫的值 | 粗略含义类比 |
|---|---|---|---|
| 第 1 维 | 是否是动物? | 0.72 | 是动物,得分高 |
| 第 2 维 | 亲和力/可爱度 | 0.35 | 稍微可爱 |
| 第 3 维 | 体型大小(抽象) | 0.11 | 比较小 |
| 第 4 维 | 家养 vs 野外 | 0.80 | 更偏向家养 |
那么此时词元就嵌入了向量值,如下:
| Token ID | 词语 | 嵌入向量(4维) |
|---|---|---|
| 2001 | 小猫 | [0.72, 0.35, 0.11, 0.80] |
| 2002 | 小狗 | [0.70, 0.38, 0.14, 0.78] |
| 1002 | 喜欢 | [0.10, 0.93, 0.21, 0.11] |
现在,“小猫”和“小狗”不再是冰冷的词元ID,而是“位置相近的向量”,如下表所示:
| 对比项 | 小猫 🐱 | 小狗 🐶 | 差异分析 |
|---|---|---|---|
| 词元ID | 2001 | 2002 | 没有语义 |
| 嵌入向量 | [0.72, 0.35, 0.11, 0.80] | [0.70, 0.38, 0.14, 0.78] | 两者向量“很接近” |
| 结论 | 表示语义上很相似的动物 | 表示语义上很相似的动物 | 模型会把它们“当成相似概念”处理 |
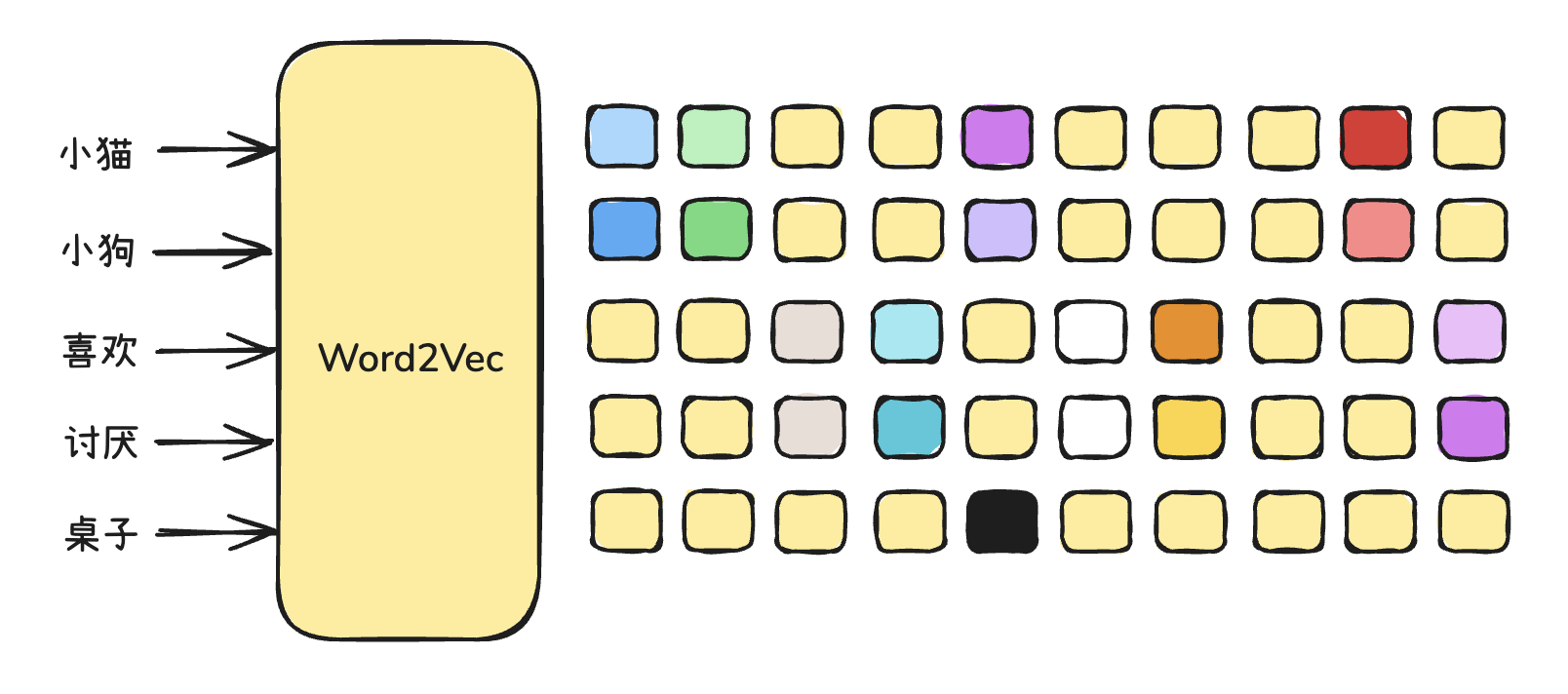
我们可以将高维向量投影成二维空间来“可视化”它们之间的语义关系:
相似的词会靠得更近。
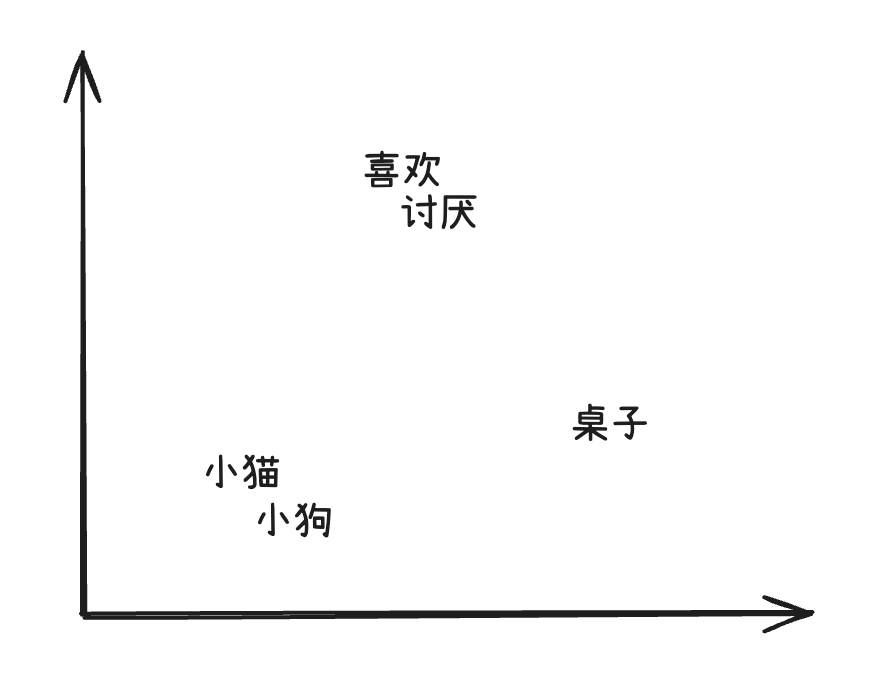
- “小猫”和“小狗”这种意思相近的词元,会靠得更近。
- “喜欢”这种语义不同的词,会离它们稍远一些。
- “讨厌”“桌子”这种不相关的词,也会离得比较远。
通过向词元嵌入向量信息,能够带来如下的好处:
- 传递语义相似性:相似词向量靠近。
- 支持上下文学习:嵌入可更新。
- 可参与数学运算:词向量支持加减。
- 输入给神经网络:向量可计算梯度。
Word2Vec
文本、文字 TO Vec(向量那个单词的缩写)
2013年,托马斯・米克洛夫和他 Google 的同事们开发了 Word2Vec 算法,Word2Vec 采用了一种高效的方法来学习词汇的连续向量表示,这种方法将词汇表中的每个词都表示成固定长度的向量,从而使在大规模数据集上进行训练变得可行。
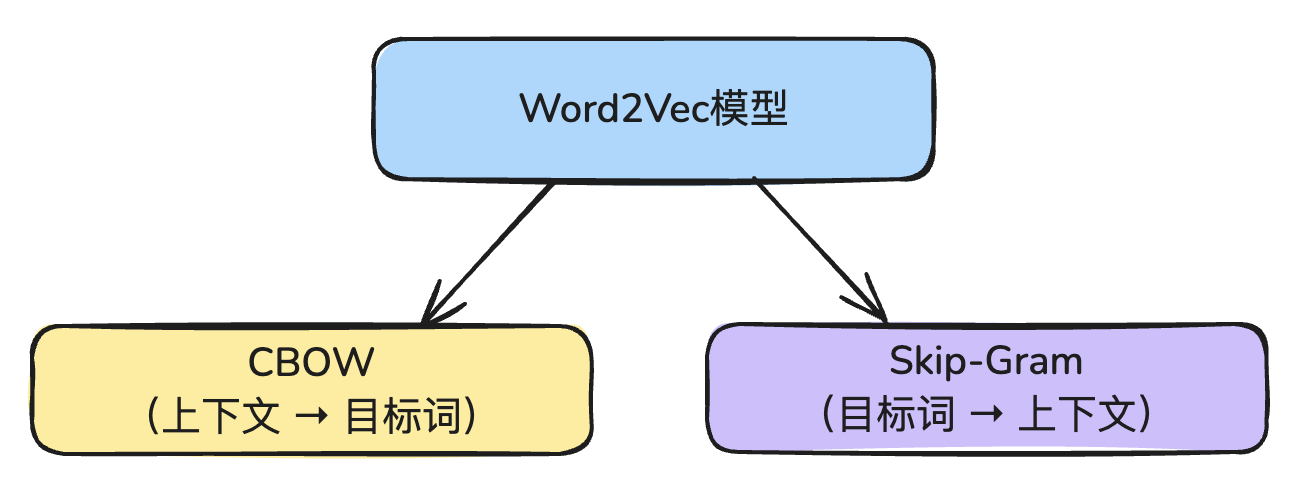
Word2Vec 有两种训练方式:
- CBOW模型
- Skip-Gram模型
这两种刚好是相反的。
1. CBOW模型
CBOW模型的核心思想是:给定一个词的上下文(前后词),预测中心词(目标词)。
例如有如下句子:
我 喜欢 吃 苹果
当输入上下文(“我”,“吃”)的时候,模型能够预测出“喜欢”。
2. Skip-Gram模型
Skip-Gram模型则刚好相反,核心思想是:给定中心词,预测它的上下文词。
仍然还是这个句子:
我 喜欢 吃 苹果
当输入中心词:“喜欢”的时候,模型能够预测上下文词:“我”、“吃”。
两者的对比
| 比较项 | CBOW | Skip-Gram |
|---|---|---|
| 训练目标 | 预测中心词 | 预测上下文 |
| 输入是什么? | 上下文词(多个) | 中心词(一个) |
| 输出是什么? | 中心词(一个) | 上下文词(多个) |
| 训练速度 | 快 | 慢 |
| 对稀有词表现 | 一般 | 更好 |
| 语义表达能力 | 差一些 | 更强 |
| 适合场景 | 大词频、高效率、短上下文窗口 | 稀有词、多语义任务、大语料 |
在训练 Word2Vec 时,可以选择使用其中一种。
在训练 Word2Vec 时,只需在代码中指定:
sg=0表示使用 CBOW 模型sg=1表示使用 Skip-Gram 模型
代码实践
train_word2vec.py 文件,该文件用于做训练工作的:
import Word2Vec from gensim.models
// 拿出牛奶从冰箱里
from gensim.models import Word2Vec
# 从冰箱里拿出牛奶
# 示例语料
sentences = [
["i", "love", "deep", "learning"],
["i", "love", "nlp"],
["deep", "learning", "is", "fun"],
["nlp", "is", "a", "part", "of", "ai"],
["word2vec", "is", "a", "powerful", "embedding"]
]
# 训练模型
model = Word2Vec(sentences, vector_size=100, window=2, min_count=1, sg=1)
# 保存模型
model.save("word2vec.model")
print("模型训练完成并已保存。")
test_word2vec.py 用于测试:
from gensim.models import Word2Vec
# 加载模型
model = Word2Vec.load("word2vec.model")
# 获取某个词的词向量
print("词向量(nlp):")
print(model.wv["nlp"])
# 找出最相似的词
print("\n与 'nlp' 最相似的词:")
print(model.wv.most_similar("nlp", topn=3))
# 计算两个词的相似度
print("\n'deep' 和 'learning' 的相似度:")
print(model.wv.similarity("deep", "learning"))